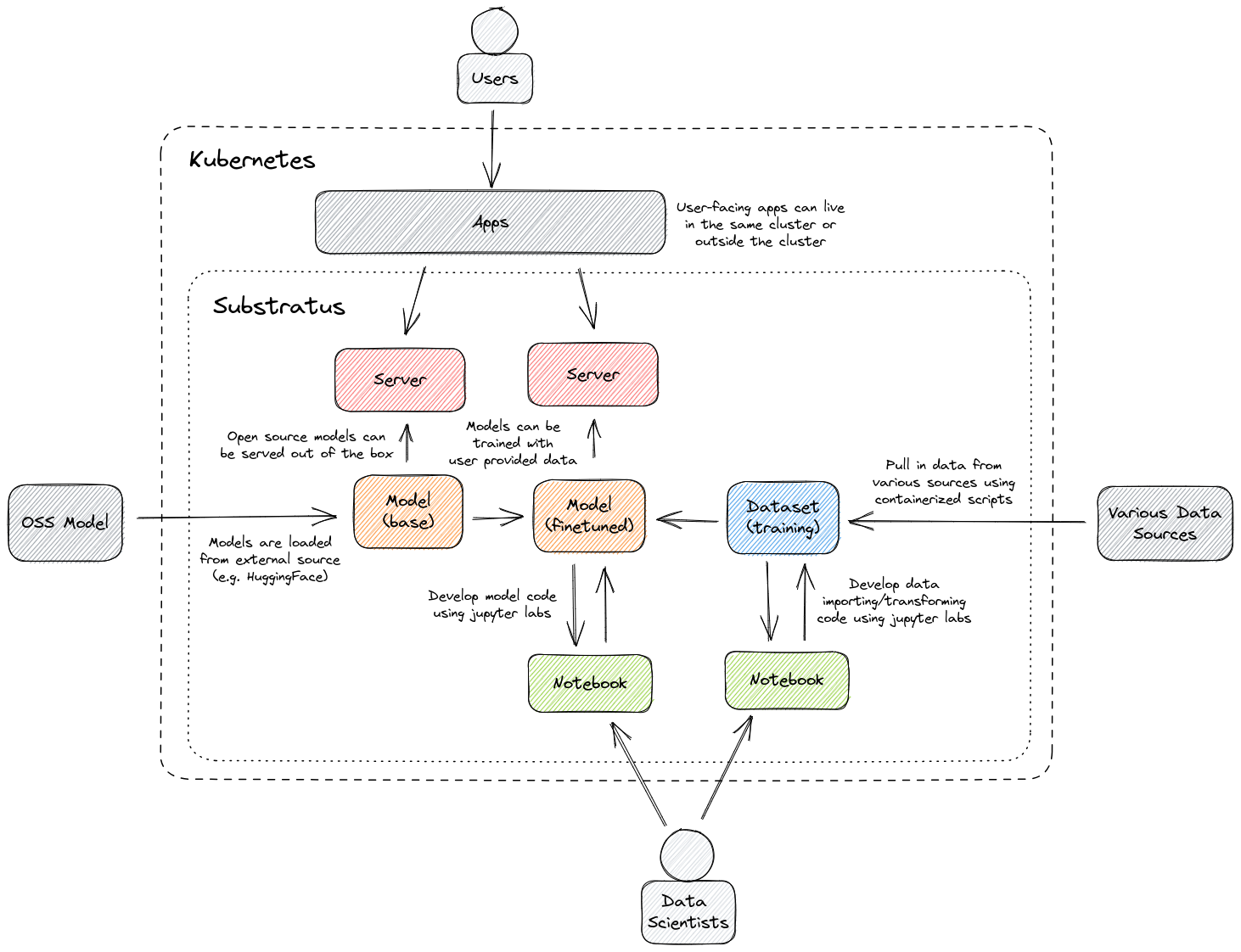
Overview
Substratus extends the Kubernetes control plane to orchestrate the full lifecycle of machine learning models. It does this by introducing new custom resources into the Kubernetes API: Model, Server, Dataset, Notebook. A set of controllers, bundled together into a single Deployment respond to these new resource types. Substratus can be described as a Kubernetes Operator as it automates the orchestration of common ML tasks: packaging models local to the infrastructure, packaging ML jobs into containers, pulling and transforming datasets, running training jobs, managing dynamic notebook development environments.
Models
The Model resource is at the center of Substratus. A Model object represents an instance of a ML model (source code bundled together with weights and biases). A Model object can describe various sources for a model: Git (Substratus will clone the repo and build a container containing the model), or another Model coupled with a training Dataset (Substratus will run a training Job on the base Model with the provided data, and build a new container image containing the trained model). All other Substratus resources exist to facilitate the progression of Model objects.
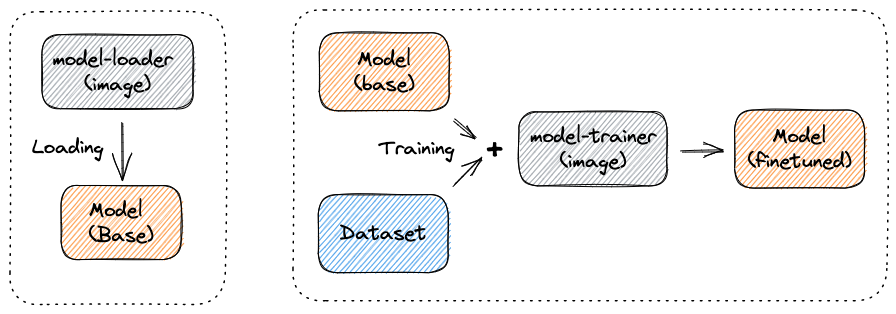
Example of a Model used to import Falcon 40B from HuggingFace:
apiVersion: substratus.ai/v1
kind: Model
metadata:
name: falcon-40b
spec:
image: substratusai/model-loader-huggingface
params:
name: tiiuae/falcon-40b
Servers
The Server resource is responsible for exposing the a Model with a HTTP API for inference.
Give GitHub issue #66 a thumbs up if support for Embeddings is important to you.
Example of a Server that will serve Falcon 40B:
apiVersion: substratus.ai/v1
kind: Server
metadata:
name: falcon-40b
spec:
image: substratusai/model-server-basaran
model:
name: falcon-40b
resources:
gpu:
type: nvidia-l4
count: 4
Datasets
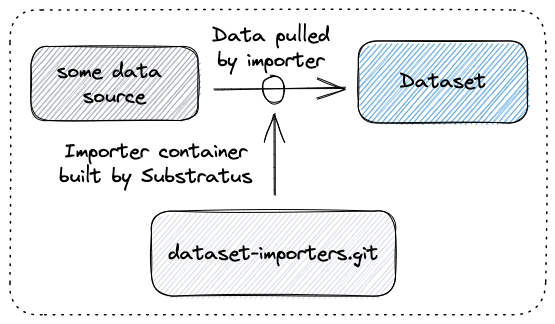
The Dataset resource facilitates the importing and transformation of public and private data sources. A Dataset object points to source code that will be used for data importing. Substratus will containerize this code and run it in the cluster, storing the resulting data in a bucket. When referenced from a Model object, Substratus will mount the data into the Model training Job.
Notebooks
The Notebook resource facilitates the development of ML source code. Unlike regular applications which can typically be developed on modest laptops, developing a ML model typically requires high performance compute (i.e. GPUs with lots of memory). A Notebook object represents an instance of a Jupyter Notebook environment that is running on beefy hardware within a Kubernetes cluster. Substratus tooling, such as the kubectl open notebook plugin, allows developers to open these notebooks on their local machines.
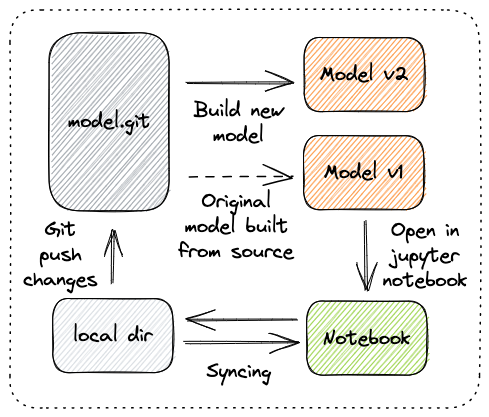
Read more about what makes Substratus Notebooks unique.